


[ad_1]
A leaked Google memo offers a point by point summary of why Google is losing to open source AI and suggests a path back to dominance and owning the platform.
The memo opens by acknowledging their competitor was never OpenAI and was always going to be Open Source.
Cannot Compete Against Open Source
Further, they admit that they are not positioned in any way to compete against open source, acknowledging that they have already lost the struggle for AI dominance.
They wrote:
“We’ve done a lot of looking over our shoulders at OpenAI. Who will cross the next milestone? What will the next move be?
But the uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI. While we’ve been squabbling, a third faction has been quietly eating our lunch.
I’m talking, of course, about open source.
Plainly put, they are lapping us. Things we consider “major open problems” are solved and in people’s hands today.”
The bulk of the memo is spent describing how Google is outplayed by open source.
And even though Google has a slight advantage over open source, the author of the memo acknowledges that it is slipping away and will never return.
The self-analysis of the metaphoric cards they’ve dealt themselves is considerably downbeat:
“While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly.
Open-source models are faster, more customizable, more private, and pound-for-pound more capable.
They are doing things with $100 and 13B params that we struggle with at $10M and 540B.
And they are doing so in weeks, not months.”
Large Language Model Size is Not an Advantage
Perhaps the most chilling realization expressed in the memo is Google’s size is no longer an advantage.
The outlandishly large size of their models are now seen as disadvantages and not in any way the insurmountable advantage they thought them to be.
The leaked memo lists a series of events that signal Google’s (and OpenAI’s) control of AI may rapidly be over.
It recounts that barely a month ago, in March 2023, the open source community obtained a leaked open source model large language model developed by Meta called LLaMA.
Within days and weeks the global open source community developed all the building parts necessary to create Bard and ChatGPT clones.
Sophisticated steps such as instruction tuning and reinforcement learning from human feedback (RLHF) were quickly replicated by the global open source community, on the cheap no less.
- Instruction tuning
A process of fine-tuning a language model to make it do something specific that it wasn’t initially trained to do. - Reinforcement learning from human feedback (RLHF)
A technique where humans rate a language models output so that it learns which outputs are satisfactory to humans.
RLHF is the technique used by OpenAI to create InstructGPT, which is a model underlying ChatGPT and allows the GPT-3.5 and GPT-4 models to take instructions and complete tasks.
RLHF is the fire that open source has taken from
Scale of Open Source Scares Google
What scares Google in particular is the fact that the Open Source movement is able to scale their projects in a way that closed source cannot.
The question and answer dataset used to create the open source ChatGPT clone, Dolly 2.0, was entirely created by thousands of employee volunteers.
Google and OpenAI relied partially on question and answers from scraped from sites like Reddit.
The open source Q&A dataset created by Databricks is claimed to be of a higher quality because the humans who contributed to creating it were professionals and the answers they provided were longer and more substantial than what is found in a typical question and answer dataset scraped from a public forum.
The leaked memo observed:
“At the beginning of March the open source community got their hands on their first really capable foundation model, as Meta’s LLaMA was leaked to the public.
It had no instruction or conversation tuning, and no RLHF.
Nonetheless, the community immediately understood the significance of what they had been given.
A tremendous outpouring of innovation followed, with just days between major developments…
Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker.
Many of the new ideas are from ordinary people.
The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.”
In other words, what took months and years for Google and OpenAI to train and build only took a matter of days for the open source community.
That has to be a truly frightening scenario to Google.
It’s one of the reasons why I’ve been writing so much about the open source AI movement as it truly looks like where the future of generative AI will be in a relatively short period of time.
Open Source Has Historically Surpassed Closed Source
The memo cites the recent experience with OpenAI’s DALL-E, the deep learning model used to create images versus the open source Stable Diffusion as a harbinger of what is currently befalling Generative AI like Bard and ChatGPT.
Dall-e was released by OpenAI in January 2021. Stable Diffusion, the open source version, was released a year and a half later in August 2022 and in a few short weeks overtook the popularity of Dall-E.
This timeline graph shows how fast Stable Diffusion overtook Dall-E:
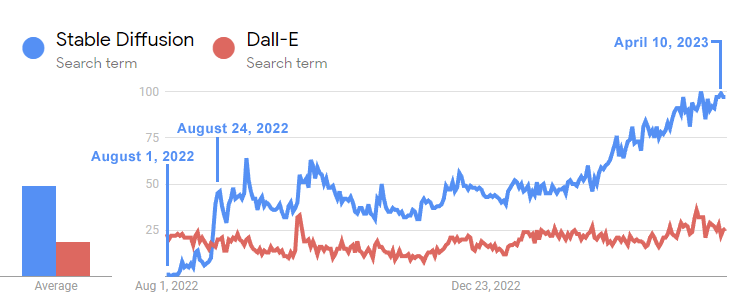
The above Google Trends timeline shows how interest in the open source Stable Diffusion model vastly surpassed that of Dall-E within a matter of three weeks of its release.
And though Dall-E had been out for a year and a half, interest in Stable Diffusion kept soaring exponentially while OpenAI’s Dall-E remained stagnant.
The existential threat of similar events overtaking Bard (and OpenAI) is giving Google nightmares.
The Creation Process of Open Source Model is Superior
Another factor that’s alarming engineers at Google is that the process for creating and improving open source models is fast, inexpensive and lends itself perfectly to a global collaborative approach common to open source projects.
The memo observes that new techniques such as LoRA (Low-Rank Adaptation of Large Language Models), allow for the fine-tuning of language models in a matter of days with exceedingly low cost, with the final LLM comparable to the exceedingly more expensive LLMs created by Google and OpenAI.
Another benefit is that open source engineers can build on top of previous work, iterate, instead of having to start from scratch.
Building large language models with billions of parameters in the way that OpenAI and Google have been doing is not necessary today.
Which may be the point that Sam Alton recently was hinting at when he recently said that the era of massive large language models is over.
The author of the Google memo contrasted the cheap and fast LoRA approach to creating LLMs against the current big AI approach.
The memo author reflects on Google’s shortcoming:
“By contrast, training giant models from scratch not only throws away the pretraining, but also any iterative improvements that have been made on top. In the open source world, it doesn’t take long before these improvements dominate, making a full retrain extremely costly.
We should be thoughtful about whether each new application or idea really needs a whole new model.
…Indeed, in terms of engineer-hours, the pace of improvement from these models vastly outstrips what we can do with our largest variants, and the best are already largely indistinguishable from ChatGPT.”
The author concludes with the realization that what they thought was their advantage, their giant models and concomitant prohibitive cost, was actually a disadvantage.
The global-collaborative nature of Open Source is more efficient and orders of magnitude faster at innovation.
How can a closed-source system compete against the overwhelming multitude of engineers around the world?
The author concludes that they cannot compete and that direct competition is, in their words, a “losing proposition.”
That’s the crisis, the storm, that’s developing outside of Google.
If You Can’t Beat Open Source Join Them
The only consolation the memo author finds in open source is that because the open source innovations are free, Google can also take advantage of it.
Lastly, the author concludes that the only approach open to Google is to own the platform in the same way they dominate the open source Chrome and Android platforms.
They point to how Meta is benefiting from releasing their LLaMA large language model for research and how they now have thousands of people doing their work for free.
Perhaps the big takeaway from the memo then is that Google may in the near future try to replicate their open source dominance by releasing their projects on an open source basis and thereby own the platform.
The memo concludes that going open source is the most viable option:
“Google should establish itself a leader in the open source community, taking the lead by cooperating with, rather than ignoring, the broader conversation.
This probably means taking some uncomfortable steps, like publishing the model weights for small ULM variants. This necessarily means relinquishing some control over our models.
But this compromise is inevitable.
We cannot hope to both drive innovation and control it.”
Open Source Walks Away With the AI Fire
Last week I made an allusion to the Greek myth of the human hero Prometheus stealing fire from the gods on Mount Olympus, pitting the open source to Prometheus against the “Olympian gods” of Google and OpenAI:
I tweeted:
“While Google, Microsoft and Open AI squabble amongst each other and have their backs turned, is Open Source walking off with their fire?”
The leak of Google’s memo confirms that observation but it also points at a possible strategy change at Google to join the open source movement and thereby co-opt it and dominate it in the same way they did with Chrome and Android.
Read the leaked Google memo here:
Google “We Have No Moat, And Neither Does OpenAI”
[ad_2]
Source link